
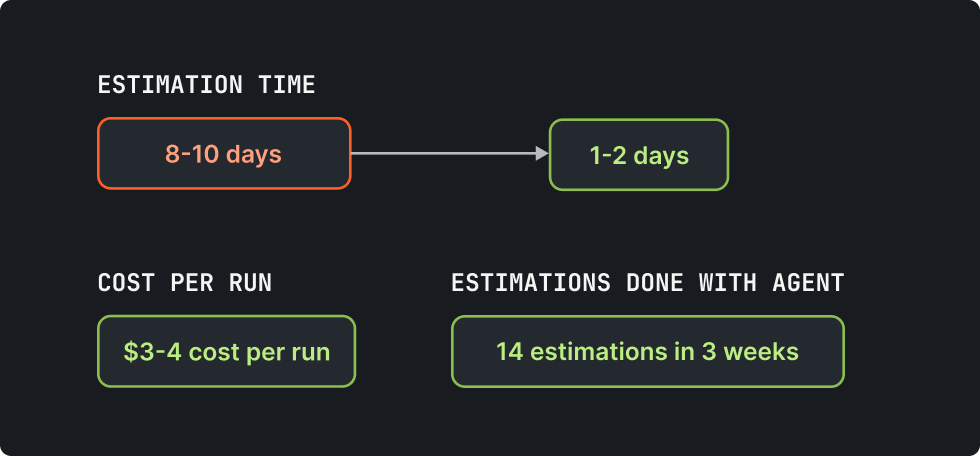
At Blazity, our estimation workflow used to take 8 to 10 days. An RFP would come in, a senior engineer would read it, pull context from past projects, write a Google Doc proposal, build a spreadsheet breakdown, go back and forth on scope questions, and eventually deliver something to sales. I built an AI agent that does most of that work autonomously. It reads RFP documents, searches 40+ past project estimations, and asks clarification questions in Slack. Then it researches the client's business model and outputs a structured Google Doc proposal with a 9-column Sheets breakdown. The whole run costs $3-4.
The hard part of building it was not the AI. It was everything around it.
Every tutorial I watched before starting made this look like a weekend project. Wire up an LLM, add some tools, ship it. What nobody mentioned was the 42 formal specs I'd end up writing, the 17 lessons I'd capture along the way, or the fact that the human-in-the-loop clarification flow would require more engineering than the AI orchestration itself.
A user sends a Slack message with !estimate and attaches a PDF or Google Doc link. That triggers a BullMQ job backed by Redis, which kicks off an orchestrator built on the Claude Agent SDK. The orchestrator runs a 5-step pipeline: analysis (search past estimations in Pinecone, classify complexity), clarification (post targeted questions to Slack, wait for human replies), value discovery (research the client's business model for value-based pricing), offer generation (fill a Google Doc template, create a Google Sheets estimation with effort, risk buffer, type classification, assumptions), and results delivery back to Slack.
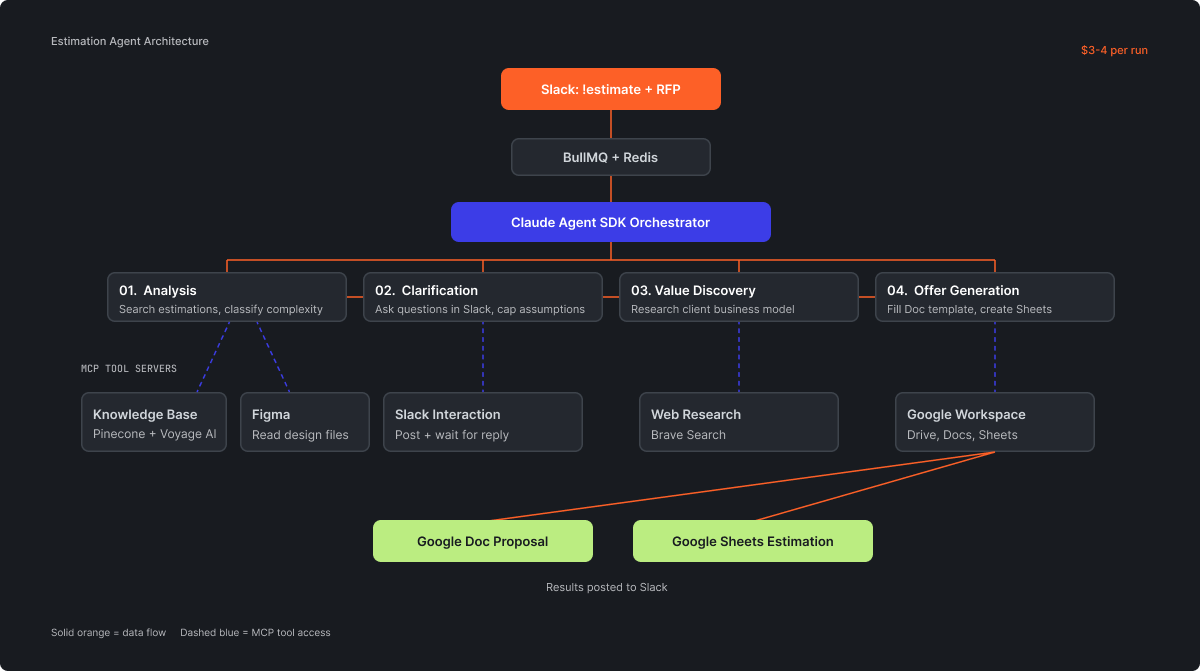
Five MCP (Model Context Protocol) servers run as isolated stdio processes: knowledge base (Pinecone with Voyage AI embeddings), Google Workspace, web research via Brave, Slack interaction, and Figma. The orchestrator's system prompt runs 1,105 lines. There's an admin panel with a real-time dashboard, live logs, and job control. From the outside, someone sends a Slack message and gets two documents back. From the inside, it's a distributed system with queuing, embedding search, human interaction loops, and document generation. None of this was in the original plan. Each piece was added because a simpler approach failed in a specific way.
MCP servers run as stdio processes. That's fine in a demo. In production, it means each server is an isolated child process that communicates over standard input and output. You cannot import modules from your main application into an MCP server. I learned this the way you learn most things in software: the build passed, the server started, and then nothing worked. The stdio protocol breaks the moment you pollute the output stream with anything that isn't a valid MCP message. A stray console.log, a shared utility that writes to stdout, an imported module with side effects. Debugging this took longer than writing the servers themselves, because the failure mode is silence. The process just hangs.
Calibration turned out to be the actual product. The orchestrator needs to know that a "simple" Next.js project is 15-25 man-days, a "medium" one is 25-60, and a "complex" one is 60-150. Team-sizing tiers, effort ranges per module type, risk buffer percentages, a 30-40% productivity reduction factor for AI-assisted work. None of this lives in the LLM. I encoded years of consulting experience into structured rules over weeks of iteration, and that calibration work is what makes the estimates accurate, not the model.
The clarification loop broke me for a while.
The agent posts a question to Slack, waits for a human reply, decides whether to ask a follow-up or move on, and does this for up to 5 rounds with a cap of 5 assumptions. Sounds simple. But the spec work for this single feature outnumbered everything I wrote for the core orchestration. What happens when the user replies with an unrelated message? What if they edit their reply after the agent already processed it? What's the timeout before the agent gives up and makes an assumption? How do you thread replies so the Slack channel stays readable? Each of these edge cases needed its own spec, its own test scenario, its own failure handling.
Deploy during an active job causes a permanent stall. BullMQ locks a job when a worker picks it up. If you deploy new code while a job is running, the worker process dies, but the lock remains in Redis. The job sat there, locked, looking healthy in the dashboard. It took two stuck jobs before I traced it to the deployment process. The fix was setting generous stalledCount and lockDuration values so BullMQ can detect orphaned jobs and retry them, but the real lesson was simpler: don't deploy during business hours when someone might be running an estimate.
Your retrieval is only as good as your source data. I'd uploaded past estimations in whatever format they originally existed in, assuming the embedding model would handle the variation. The knowledge base was nearly useless until I spent the better part of a week manually normalizing 40+ past estimations into a uniform structure. I'll spare you the details here — they're in the "what I'd do differently" section — but the short version is: standardize your data before you write a single line of agent code. One more thing about Pinecone: embeddings are immutable to the model that created them. Change your embedding model later and you re-index everything from scratch.
I tracked every engineering decision in a spec file. The project has 42 of them in .ai/specs/. Not because I'm unusually disciplined, but because this agent touches five external services, handles asynchronous human input, generates financial documents, and runs unattended. One bad assumption compounds through the entire pipeline and produces an estimate that's wrong in ways that look plausible.
Spec 31, for example, covers what happens when the Pinecone similarity search returns results below the 0.4 minimum score threshold. The agent could silently use low-confidence matches, or it could surface that it found nothing relevant and proceed with assumptions. The spec mandates the second option and requires the agent to flag the gap explicitly in the output document. Without that spec, the agent would confidently reference a vaguely related past project and produce an estimate anchored to the wrong baseline.
The 17 lessons in .ai/lessons.md are a different kind of artifact. They're not design decisions but corrections. Things that went wrong in production and the rule that prevents them from happening again. The orchestrator reads the lessons file at the start of every run. It's not fine-tuning. It's a plain-text file with rules like "never estimate a headless CMS migration below 20 man-days" and "if Pinecone returns no results above 0.4, flag the gap instead of using low-confidence matches." Simple, legible, and more effective than any automated feedback loop I've tried.
Before the agent, an estimation took 8 to 10 days from RFP receipt to delivered proposal. A senior engineer would lose parts of three or four days to it: reading the RFP, reviewing past projects, building the spreadsheet, writing the narrative, waiting on client replies, revising. The elapsed time wasn't mostly active work. It was calendar time lost to context switches, client reply lag, and scheduling around the engineer's other commitments.
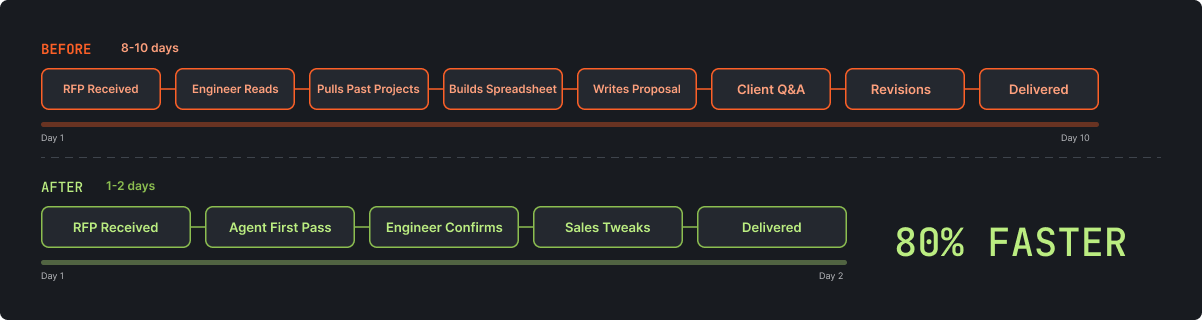
Now it takes 1 to 2 days. The agent handles the first pass: reads the RFP, searches past estimations, asks clarification questions, generates both documents. A senior engineer reviews the output, adjusts the numbers based on judgment the agent can't replicate, and confirms. Sales uses it as the base for offer creation, then tweaks positioning and pricing. The agent has processed 14 estimates in the three weeks since deployment. It's the standard workflow for all estimations now, not an experiment running alongside the old process.
Each run costs $3 to $4 in API and infrastructure spend. Estimates are more consistent now. The agent searches every past project for comparable scope instead of relying on whoever remembers a similar engagement. And pricing doesn't drift because the calibration rules apply the same way every time, regardless of who triggered the run.
I should have built this sooner. I kept treating the estimation workflow as "not urgent enough" to automate while watching it drag across two weeks, repeatedly.
The bigger mistake was data preparation. I uploaded past estimations in their original formats, assuming the agent and the embedding model would handle the variation. They didn't. Word docs next to PDFs with different layouts, Google Sheets where no two files used the same columns. The knowledge base was nearly useless until I went back and manually brought every past estimation into a uniform format. If I were starting over, I'd standardize the source documents before writing a single line of agent code. The quality of your retrieval is the quality of your source data, and no amount of prompt engineering fixes garbage embeddings.
The AI part of this project was maybe 10% of the total effort. Specs, calibration, data normalization, queue management, deploy safety, a clarification loop that needed more design work than the orchestrator. That ratio — 10% AI, 90% everything else — hasn't changed across the three production agents I've built now.
The model is the easy part. Everything around it is the work.
If you're building something similar and want to compare notes, reach out.